

IDP(지능형 문서 처리)란?
IDP는 Intelligent Document Processing의 약자로 ‘지능형 문서 처리’를 의미 합니다. NLP(자연어처리), OCR(Optical Character Reader) 기술을 사용하여 비정형 문서에서 데이터를 추출하여 구조화된 데이터 변환하여 업무에 활용합니다.

업무에 사용되는 문서는 종류와 양식이 다양하여 OCR, AI OCR로 인식하여 정보를 추출하는데는 한계가 있었습니다. 여기에 자연어처리기술과 머신러닝 기술을 추가하므로서 구조화된 데이터로 활용할 수 있게 되었습니다.
AI OCR의 기본 개념 확인하기IDP 처리 프로세스
IDP는 데이터 수집/전처리 → 문서 분류 → 데이터 추출 → 검증 → 통합 → 인사이트의 단계로 이뤄집니다. 아래 이미지는 가트너에서 제시한 기본 IDP처리 프로세스 입니다.
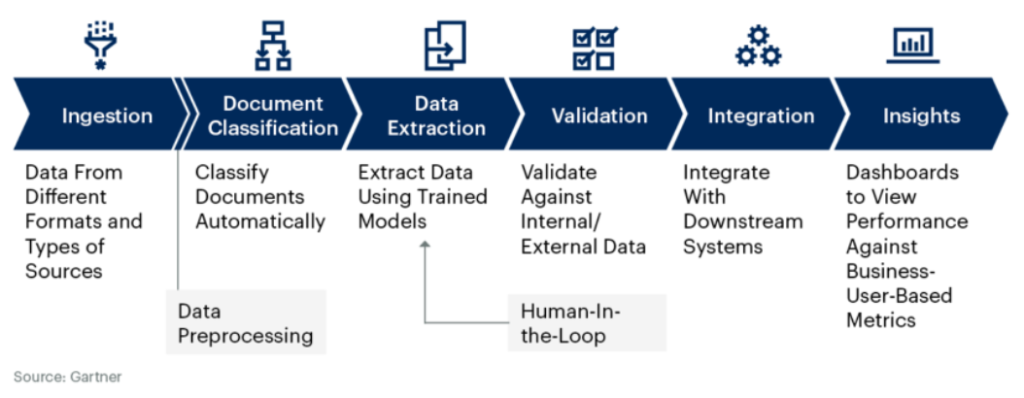
- 데이터수집/전처리: 정형, 비정형 문서를 수집하고 OCR 모듈에서 잘 인식할 수 있도록 전처리를 진행합니다.
- 문서분류: 사용될 용도와 특성에 맞춰 문서를 분류합니다. 이 과정은 필요에 따라서 데이터 추출 다음 단계에서 수행하기도 합니다.
- 데이터 추출: OCR과 NLP기술을 사용하여 문서 내에서 필요한 정보를 추출합니다. 이미지 안의 텍스트를 추출할 수도 있고 텍스트에서 의미있는 데이터를 추출할 수도 있습니다. 이 때 사람이 개입하여 성능을 개선하거나 전용 인식 모델을 만들 수 있으며 이 과정을 Human-In-th-Loop 라 합니다.
- 데이터 검증: 추출된 데이터를 검증합니다. 원본 이미지와 추출된 값을 사람이 비교하며 인식 정확도가 높은 경우 자동화를 위해서 과정을 스킵할 수도 있습니다.
- 통합/인사이트: 검증된 데이터를 통합하여 업무에 활용합니다. 이 과정에서 새로운 정보나 인사이트를 얻을 수 있습니다.
OCR과 IDP 차이점
OCR도 문서 이미지에서 데이터를 추출하는 역할을 하는데 IDP와 뭐가 다를까요?
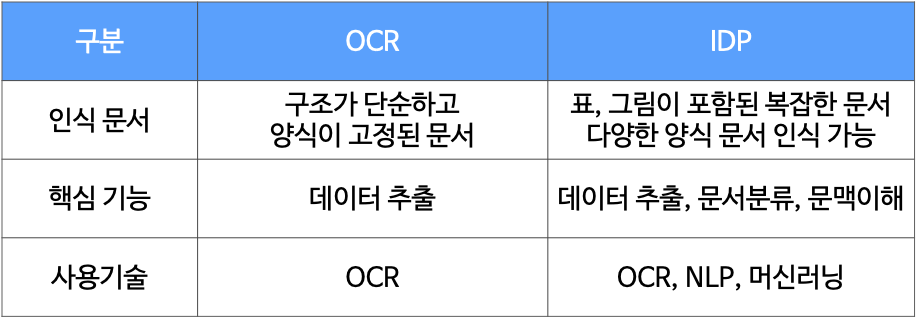
OCR에서 신용카드, 신분증 등 문서의 양식이 정해져 있는 경우에만 데이터를 추출할 수 있습니다. 최근에는 AI기술을 사용하여 형식이 정해져 있지 않은 ‘비정형 문서’에서도 데이터를 추출할 수 있지만 AI모델의 성능에 따라 추출대상이 제한적이고 시간이 지남에 따라 성능이 떨어집니다.
IDP는 그림, 표, 텍스트 등 복잡한 구성의 문서에서 데이터를 추출하고 문서를 분류합니다. 인식할 수 있는 문서의 종류도 양식에 관계 없이 확장할 수 있는 것도 큰 장점입니다.
또한 NLP 자연어처리 기술을 활용하여 문맥을 이해하여 부가적인 정보를 추출할 수 있습니다. 최근 이슈가 되고 있는 챗GPT도 기본이 되는 기술은 NLP기반 입니다.
정리하면 OCR은 데이터 추출, IDP는 OCR기능에 문서확장과 문맥이해를 더한 것이라 하겠습니다. 해당 내용을 표로 정리하면 아래와 같습니다.
IDP 활용
IDP는 문서 처리를 위한 인력과 시간을 줄이고 처리 프로세스를 자동화 할 수 있습니다.
예를 들어 고객이 제출한 가입서류에서 이름, 전화번호 등의 정보를 작업자 입력 없이 스캔하여 자동으로 처리할 수 있고 회사에서 증빙용으로 제출하는 간이 영수증에서 사용처와 비용만 추출하여 저장할 수 도 있습니다.
- 은행: 대출 신청서, 신분증, 가입 동의서 인식
- 보험: 보험금 청구를 위한 서류를 자동으로 인식
- 정부: 신청서 양식, 여권, 신분증 인식
- 제조: 운영일지, 계약서, 사업자 등록증
- 일반: 경비 영수증 인식 등