
데이터마이닝은 데이터에서 유용한 상관관계를 발견하는 것으로 데이터 예측(Predict), 분류(Classification), 군집화(Clustering), 연관(Association) 등을 통해 최적의 의사결정을 돕는데 활용할 수 있습니다.
데이터마이닝(Data Mining) 개요
- 대용량의 데이터에서 유용한 정보를 캐내는(Mining)하는 작업과 과정을 말합니다.
- 데이터의 상관관계, 패턴, 규칙 등의 특징을 찾고 이를 모형화(모델링)하여 활용합니다.
데이터 마이닝 Process
데이터마이닝은 데이터추출 부터 모델 평가까지의 과정을 통해 수행됩니다. 앞서 설명드린것 처럼 AI모델 개발과정과 유사합니다.

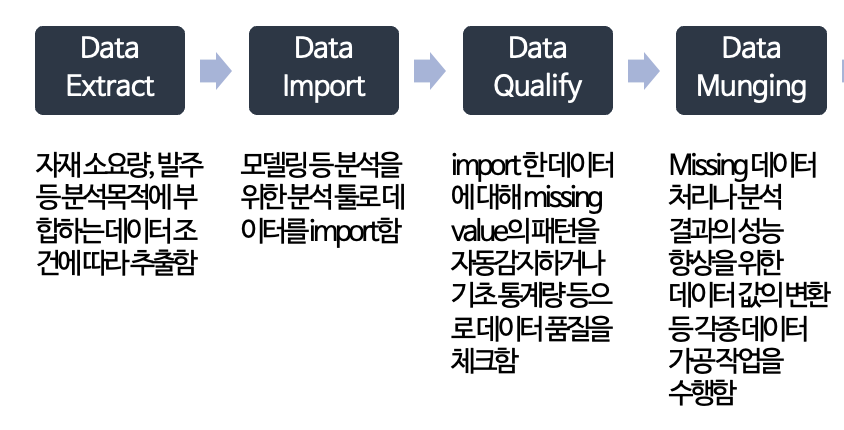
- Data Extrac(데이터 추출)
- 자재 소요량, 발주 등 분석목적에 부합하는 데이터 조건에 따라 추출함
- Data Import(데이터 불러오기)
- 모델링 등 분석을 위한 분석 툴로 데이터를 import함
- Data Qualify Check(데이터 체크)
- 분석 툴에 import한 데이터에 대해 missing value의 패턴을 자동감지하거나 기초 통계량 등으로 데이터 품질을 체크함
- Data Munging(데이터 핸들링)
- Missing 데이터 처리나 분석결과의 성능향상을 위한 데이터 값의 변환 등 각종 데이터 가공작업을 수행함
- Data Exploration(데이터 확인)
- 다차원의 데이터를 각종 필터링 기능 등을 활용하여 쉽고 빠르게 데이터의 의미를 파악할 수 있는 작업 단계임
- Data Modeling(데이터 모델링)
- 제품수요, 판매 예측하는 classification, 시간 흐름에 따라 사망의 가능성을 계산하는 생존분석 등을 실시함
- Model Assessment(모델 평가)
- 개발, 도출된 예측 모형에 대한 평가를 실시함 모형 튜닝이나 재개발 등의 결정을 하는 모형 품질진단 단계임